

Inteligência Artificial: Domínio de Jogos com Aprendizagem por Reforço
Aprendizagem por Reforço
Reinforcement Learning é um ramo da Inteligência Artificial que se inspira muito em como aprendemos no dia a dia: por meio de tentativa e erro. Imagine que você está jogando um jogo de plataforma: e o NPC (o agente) pula, corre, enfrenta inimigos e coleta moedas — tudo para maximizar a quantidade de pontos (a recompensa) ao longo da aventura. Se você cair em um buraco ou bater em um inimigo, perde pontos (recompensa negativa); se coletar moedas ou derrotar chefes, ganha pontos (recompensa positiva). Ao jogar diversas vezes, você começa a “aprender” uma sequência de ações que leva aos melhores resultados. É exatamente isso que acontece no processo de Aprendizagem por Reforço.
1. A Equação de Bellman
A Equação de Bellman é fundamental para calcular o valor de um estado, pois considera não apenas a recompensa imediata, mas também as recompensas futuras (descontadas). Isso possibilita um processo de aprendizagem iterativa, no qual o agente atualiza continuamente suas estimativas de valor até convergir para uma estratégia (política) que maximiza a soma total de recompensas. Para modelar a tomada de decisão nesse contexto, costuma-se utilizar Processos de Decisão de Markov (MDPs), que descrevem matematicamente as escolhas de um agente voltado a maximizar recompensas ao longo do tempo. Um dos elementos-chave para resolver MDPs é justamente a Equação de Bellman, pois ela relaciona o valor de um estado (o quão vantajoso é estar nele) às recompensas esperadas em estados futuros.
De forma geral, podemos pensar nos principais componentes assim:
- S → Estados (por exemplo, a posição do seu personagem em uma fase ou o estado de um tabuleiro de jogo);
- a → Ações (pular, atirar, mover para a direita, mover para a esquerda, etc.);
- R → Recompensa imediata (por exemplo, +1 ao coletar uma moeda, -1 ao receber dano de inimigo);
- γ(gamma) (gama) → Fator de desconto, que indica a importância dada às recompensas futuras (entre 0 e 1).
A Equação de Bellman para o valor de um estado pode ser escrita de forma resumida como:
![\[ V(s) = \max_a \bigl[R(s,a) + \gamma \, V(s')\bigr]. \]](https://evolvers.com.br/wp-content/ql-cache/quicklatex.com-b209117b94e58e42c2069bad9e49f98d_l3.png "Rendered by QuickLaTeX.com")
onde:
é a recompensa imediata ao tomar a ação
no estado
.
é o novo estado após executar a ação
significa que escolhemos a ação
Em um jogo, isso equivale a dizer: “Qual ação agora (pular, atirar, correr) me dá a maior soma de pontos, considerando não apenas o que ganho/perco de imediato, mas também as oportunidades (ou perigos) que se seguirão no futuro?”
 é a recompensa imediata ao tomar a ação
é a recompensa imediata ao tomar a ação  significa que escolhemos a ação
significa que escolhemos a ação

2. O “Plano” e a Política
Na maioria dos jogos, se você fosse planejar cada passo detalhadamente antes de começar (“aperte o botão A agora, depois ande dois passos para a direita, depois pule…”), qualquer mudança inesperada (como um inimigo novo ou uma armadilha oculta) poderia arruinar todo o plano. No mundo da Aprendizagem por Reforço, em vez de escrever um “plano” fixo, o agente desenvolve uma política, que indica qual ação tomar em cada estado.
Plano (no sentido de Planejamento Clássico):
É uma sequência estática de ações pré-definidas (“Primeiro vá para frente, depois vire à direita, depois pule…”).
Política (em Aprendizagem por Reforço):
É adaptativa. Em cada estado do jogo, você olha para a sua estratégia aprendida e decide a melhor ação a tomar naquele momento, mesmo que as condições mudem. Se aparecer um inimigo novo, a política deve ser capaz de lidar com isso sem precisar replanejar do zero.
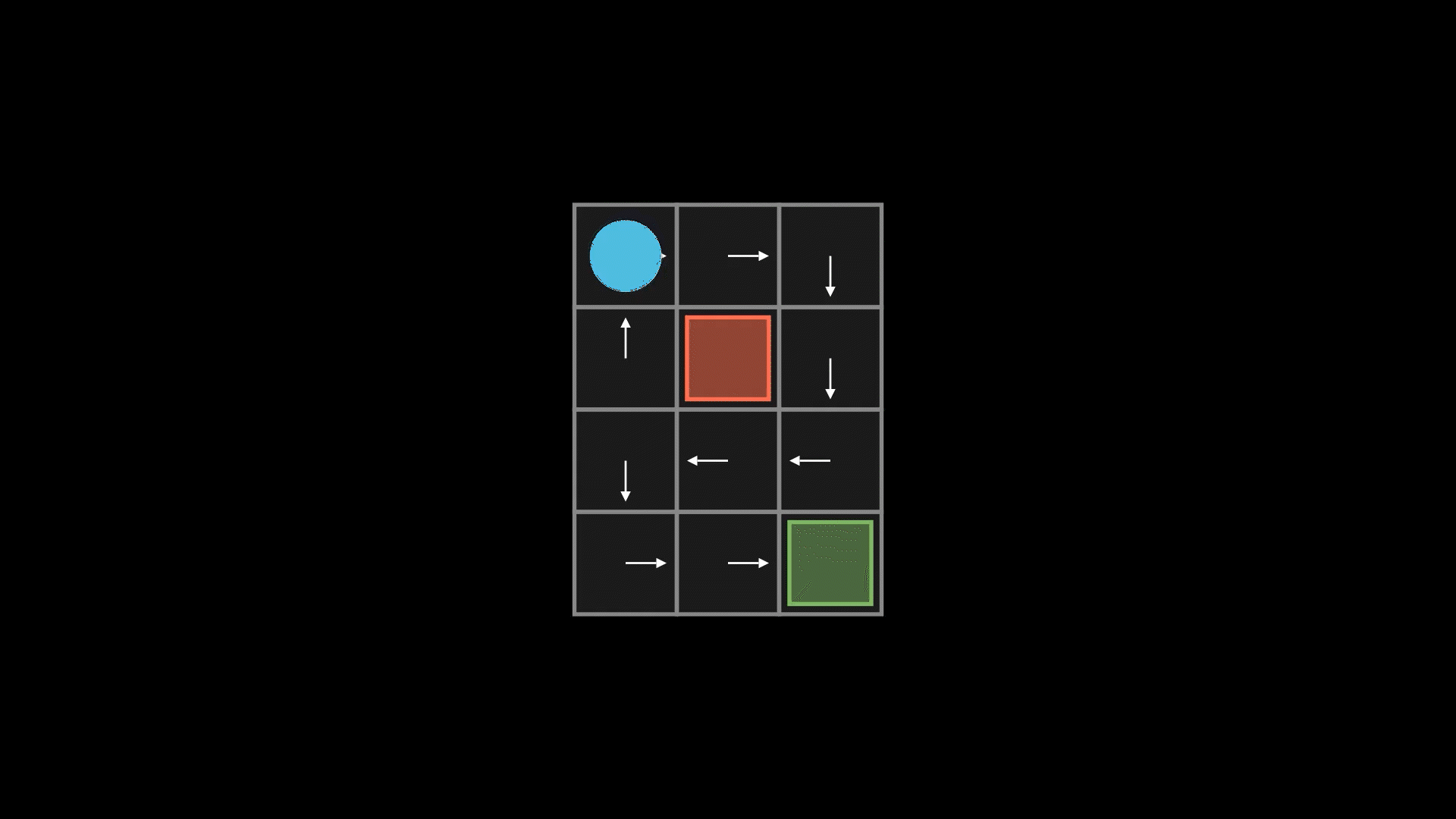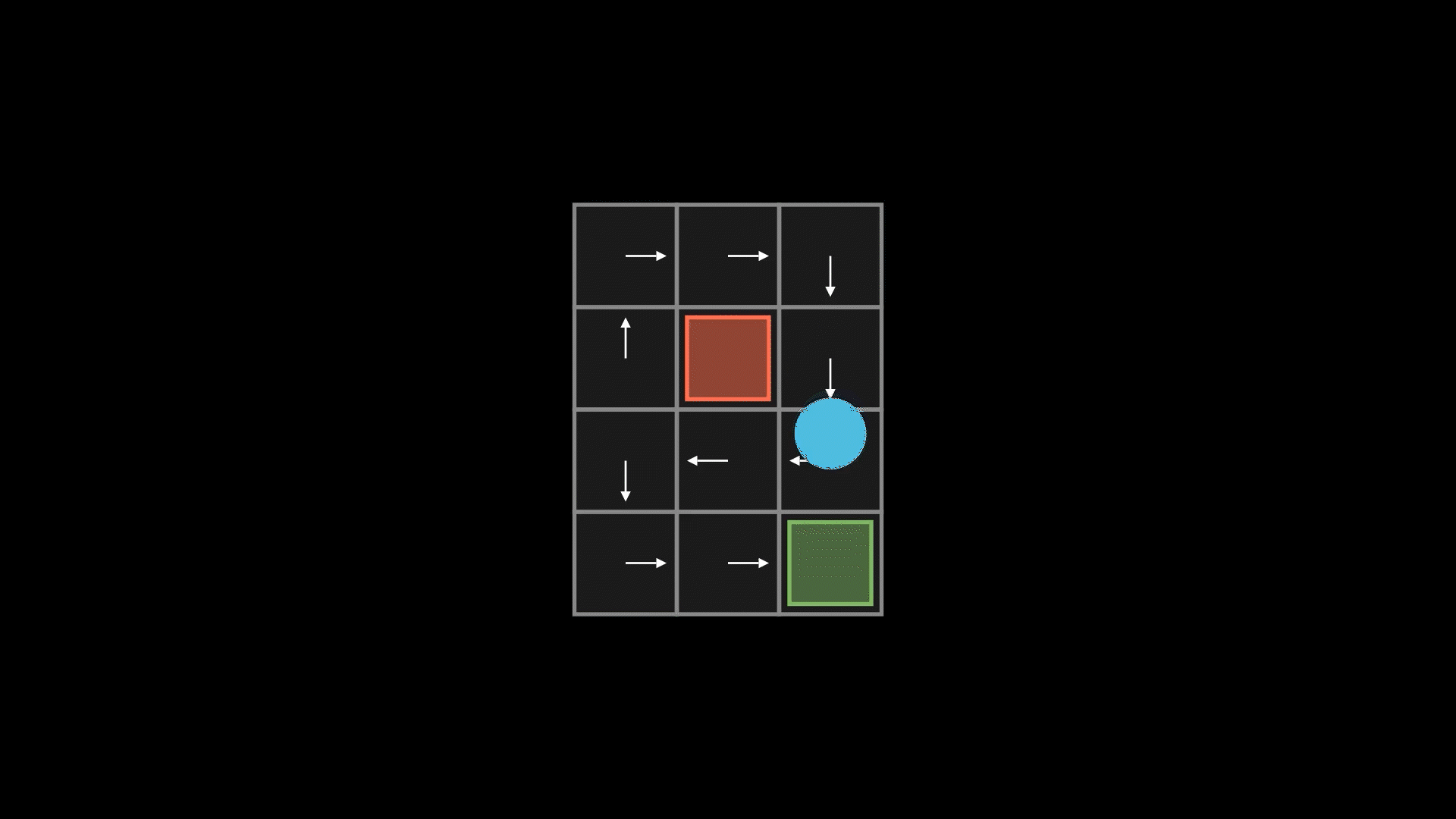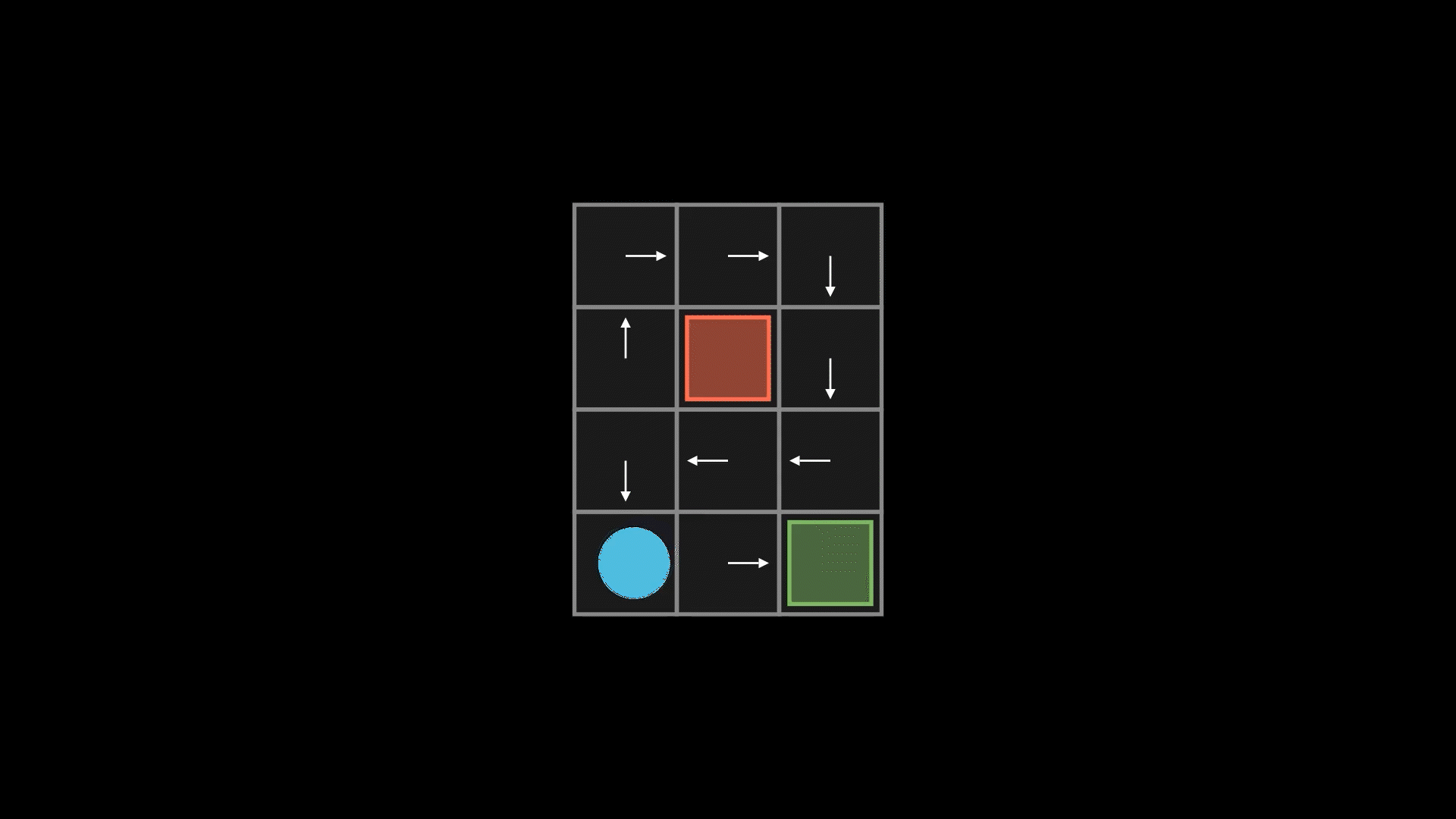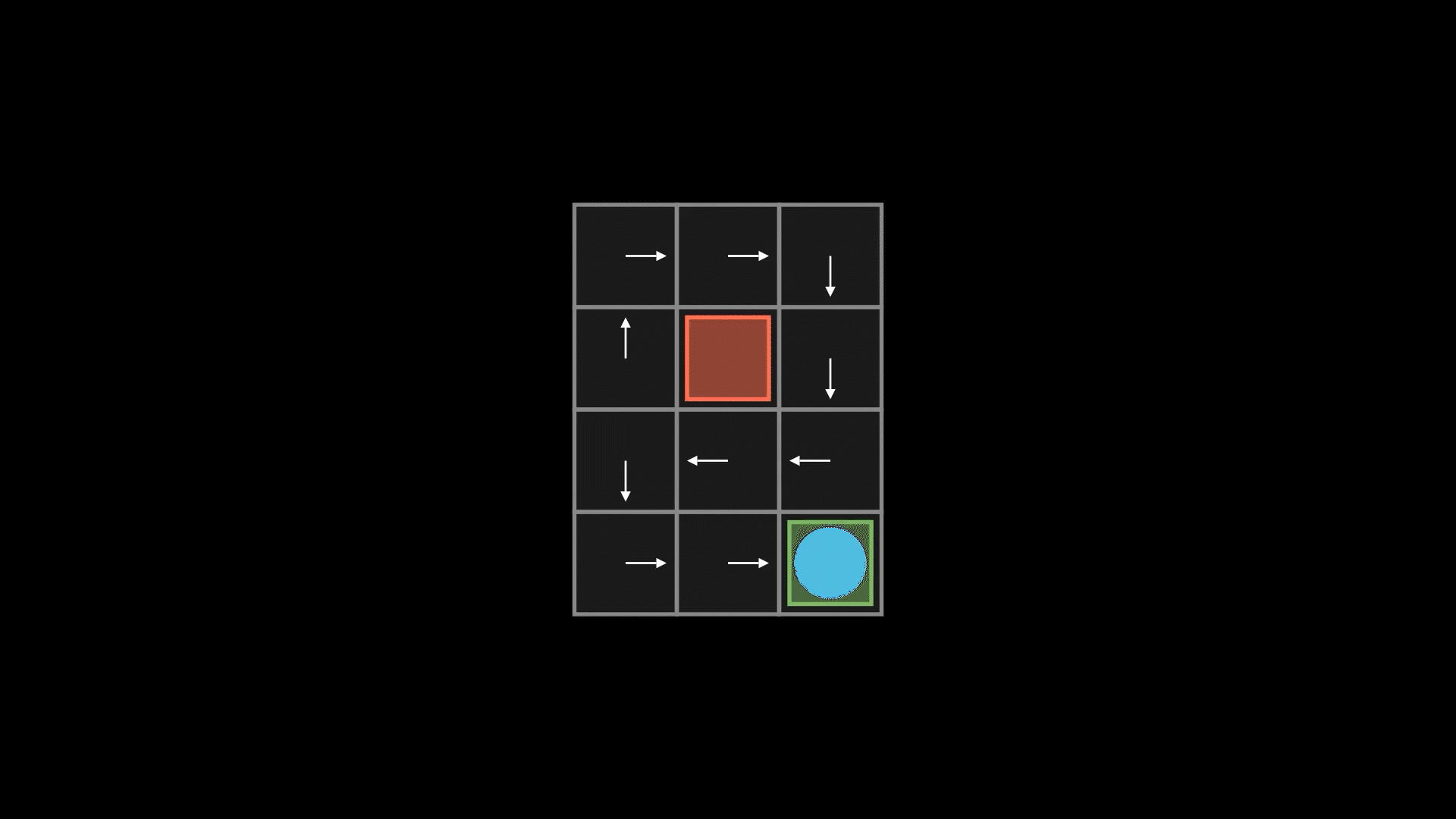
3. Componentes de um MDP
Um Processo de Decisão de Markov (MDP) é definido por um quíntuplo  :
:
Estados 
Representam as possíveis situações do jogo: posição do jogador no mapa, quantidade de vidas, tempo restante, etc.
Ações 
Possíveis movimentos ou escolhas que podem ser feitas em cada estado. Exemplos: pular, atirar, mover-se para a esquerda ou direita, abrir um baú, etc.
Função de Transição 
Determina a probabilidade de ir para um estado  dado que o agente está em
dado que o agente está em  e realiza uma ação
e realiza uma ação  . Em um jogo de plataforma mais simples (determinístico), pressionar “direita” talvez o leve sempre ao estado . Em jogos com elementos de sorte (estocásticos), pode haver uma probabilidade de escorregar ou ser empurrado para outro lado.
. Em um jogo de plataforma mais simples (determinístico), pressionar “direita” talvez o leve sempre ao estado . Em jogos com elementos de sorte (estocásticos), pode haver uma probabilidade de escorregar ou ser empurrado para outro lado.
Função de Recompensa 
Define o “ganho” (ou custo) imediato ao executar a ação no estado . Exemplo: +10 pontos por derrotar um inimigo, -5 por cair em um buraco.
Fator de Desconto 
É quanto valorizamos recompensas futuras em comparação às imediatas. Se estiver próximo de 1, damos bastante importância a recompensas de longo prazo (por exemplo, investir em estratégia para derrotar o chefão final); se estiver próximo de 0, o foco está em ganhos imediatos (pegar moedas rapidamente, mesmo que isso possa levar a penalidades futuras).
O objetivo é encontrar a política que maximize a soma das recompensas recebidas ao longo do tempo, considerando o fator de desconto.
4. Determinismo x Não Determinismo
4.1. No Ambiente
- Determinístico: Uma dada ação em um estado leva sempre ao mesmo próximo estado. Pense num jogo de plataforma simples, sem elementos aleatórios: apertou “pular” na beira do penhasco, você sempre cairá no próximo bloco se o cálculo do salto for suficiente.
- Estocástico (Não Determinístico): A mesma ação em um mesmo estado pode levar a diferentes próximos estados, com certas probabilidades. Imagine um piso escorregadio: ao andar para frente, há 80% de chance de continuar reto e 20% de chance de derrapar para outro lugar.
4.2. Na Política do Agente
- Política Determinística: Para cada estado, escolhe sempre a mesma ação.
- Política Estocástica: Para cada estado, há uma probabilidade de escolher cada ação. Exemplo: em 90% das vezes atira, mas em 10% das vezes pula, para explorar possibilidades.
5. “Living Penalty” – Exemplo em Jogos
Para tornar tudo mais concreto, imagine que seu personagem recebe penalidades contínuas (living penalty) a cada segundo que passa em uma fase, encorajando você a terminar o estágio mais rapidamente. Esse sistema de penalidades funciona como um “relógio” que diminui sua pontuação ao longo do tempo. Quanto mais você demora, mais pontos perde. Em contrapartida, cada moeda coletada, cada inimigo derrotado e cada fase concluída concede recompensas positivas.
- Se você ficar parado, a penalidade de tempo vai se acumulando (reduzindo sua pontuação total).
- Se você se arriscar e avançar rápido, pode cair em armadilhas e perder ainda mais pontos.
- Se for muito cauteloso, talvez a penalidade de “vida parada” (tempo gasto) também tire a sua pontuação.
Por meio de tentativas e erros, seu agente virtual (ou você mesmo, como jogador) aprende a dosar entre “correr risco” e “agir com cautela”, buscando o melhor balanço entre ganhar moedas, evitar inimigos e não perder tempo — tudo para maximizar a soma total de recompensas ao final.
6. Conclusão
A Aprendizagem por Reforço é uma forma versátil e poderosa de treinar agentes em ambientes de jogo (e em muitos outros contextos). Em vez de ter um plano fixo que pode falhar diante de eventos inesperados, o agente desenvolve políticas que podem se ajustar dinamicamente. A Equação de Bellman nos dá a base matemática para atualizar as estimativas de valor de cada estado, levando em conta recompensas imediatas e futuras. E, no fim das contas, a grande magia da Aprendizagem por Reforço acontece quando o agente experimenta — apanhando aqui, coletando pontos ali — e, gradualmente, descobre a melhor forma de jogar para alcançar o objetivo final: a maior recompensa possível.
Em termos de design de jogos, isso se traduz em criar ambientes e recompensas que incentivem os jogadores (ou agentes) a encontrar estratégias que são, ao mesmo tempo, eficientes e adaptáveis. Assim, quer você esteja programando um robô para recolher recursos em um planeta distante ou treinando um personagem de plataforma para chegar ao castelo final, os princípios de MDPs, políticas e recompensas continuam sendo a base para solucionar problemas de tomada de decisão sequencial.
Para saber mais, sobre inteligência artificial para jogos pule aqui
Curso de jogo 3D
Nosso canal